Wardley mapping the service orchestration ecosystem (2014).
In Uber’s 2014 service migration strategy, we explore how to navigate the move from a Python monolith to a services-oriented architecture while also scaling with user traffic that doubled every six months.
This Wardley map explores how orchestration frameworks were evolving during that period to be used as an input into determining the most effective path forward for Uber’s Infrastructure Engineering team.
Reading this map
To quickly understand this Wardley Map, read from top to bottom. If you want to review how this map was written, then you should read section by section from the bottom up, starting with Users, then Value Chains, and so on.
More detail on this structure in Refining strategy with Wardley Mapping.
How things work today
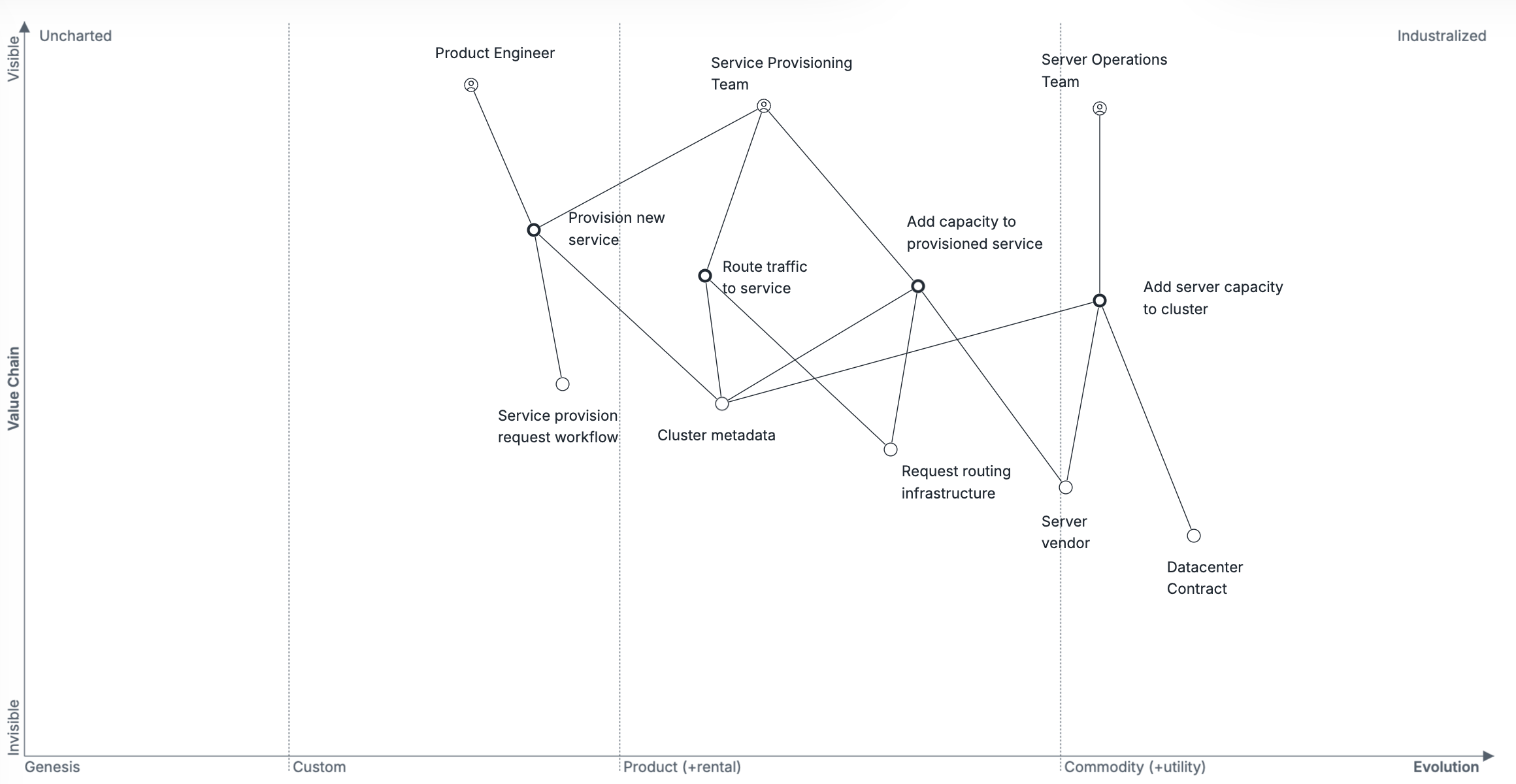
There are three primary internal teams involved in service provisioning. The Service Provisioning Team abstracts applications developed by Product Engineering from servers managed by the Server Operations Team. As more servers are added to support application scaling, this is invisible to the applications themselves, freeing Product Engineers to focus on what the company values the most: developing more application functionality.
Wardley map for service orchestration
The challenges within the current value chain are cost-efficient scaling, reliable deployment, and fast deployment. All three of those problems anchor on the same underlying problem of resource scheduling. We want to make a significant investment into improving our resource scheduling, and believe that understanding the industry’s trend for resource scheduling underpins making an effective choice.
Transition to future state
Most interesting cluster orchestration problems are anchored in cluster metadata and resource scheduling. Request routing, whether through DNS entries or allocated ports, depends on cluster metadata. Mapping services to a fleet of servers depends on resource scheduling managing cluster metadata. Deployment and autoscaling both depend on cluster metadata.

Pipeline showing progression of service orchestration over time
This is also an area where we see significant changes occurring in 2014.
Uber initially solved this problem using Clusto, an open-source tool released by Digg with goals similar to Hashicorp’s Consul but with limited adoption. We also used Puppet for configuring servers, alongside custom scripting. This has worked, but has required custom, ongoing support for scheduling. The key question we’re confronted with is whether to build our own scheduling algorithms (e.g. bin packing) or adopt a different approach. It seems clear that the industry intends to directly solve this problem via two paths: relying on Cloud providers for orchestration (Amazon Web Services, Google Cloud Platform, etc) and through open-source scheduling frameworks such as Mesos and Kubernetes.
Industry peers with more than five years of infrastructure experience are almost unanimously adopting open-source scheduling frameworks to better support their physical infrastructure. This will give them a tool to perform a bridged migration from physical infrastructure to cloud infrastructure.
Newer companies with less existing infrastructure are moving directly to the cloud, and avoiding the orchestration problem entirely. The only companies not adopting one of these two approaches are extraordinarily large and complex (think Google or Microsoft) or allergic to making any technical change at all.
From this analysis, it’s clear that continuing our reliance on Clusto and Puppet is going to be an expensive investment that’s not particularly aligned with the industry’s evolution.
User & Value Chains
This map focuses on the orchestration ecosystem within a single company, with a focus on what did, and did not, stay the same from roughly 2008 to 2014. It focuses in particular on three users:
- Product Engineers are focused on provisioning new services, and then deploying new versions of that service as they make changes. They are wholly focused on their own service, and entirely unaware of anything beneath the orchestration layer (including any servers).
- Service Provisioning Team focuses on provisioning new services, orchestrating resources for those services, and routing traffic to those services. This team acts as the bridge between the Product Engineers and the Server Operations Team.
- Server Operations Team is focused on adding server capacity to be used for orchestration. They work closely with the Service Provisioning Team, and have no contact with the Product Engineers.
It’s worth acknowledging that, in practice, these are artificial aggregates of multiple underlying teams. For example, routing traffic between services and servers is typically handled by a Traffic or Service Networking team. However, these omissions are intended to clarify the distinctions relevant to the evolution of orchestration tooling.
First published at lethain.com/wardley-compute-ecosystem/